
Monitorando VMware vSphere com TIG Stack no Raspberry Pi 4 utilizando conteiners Docker é o que iremos abordar neste artigo super detalhado.
No artigo anterior, ensinei a vocês de forma detalhada como transformar seu Raspberry Pi 4 numa “máquina de orquestração com Docker e Docker Compose“. Se você se perdeu no caminho, dá uma olhada nesse link AQUI para aprender. Como eu havia dito, aquele era o pontapé inicial, porque agora vamos explorar o poder que temos nas mãos ao se utilizar conteiners Docker. E eu já começo por alto, utilizando o TIG Stack para monitorar nosso ambiente VMware vSphere! E é claro, utilizando uma linguagem simples e detalhada.

Mas afinal, o que é esse tal de TIG Stack? É de comer ou de beber?
TIG é um acrônimo que combina três poderosas ferramentas: Telegraf, InfluxDB e Grafana. Ou seja, TIG é na verdade um time. Vamos detalhar cada integrante desse time:
Telegraf: O “mensageiro” da turma, é o agente que coleta e envia todas as métricas para o InfluxDB. Imagine ele como sendo um cara muito curioso, que quer saber de tudo e está sempre coletando informações. Ou, o Sherlock Holmes do nosso stack, vasculhando todos os cantos em busca de pistas (métricas) e enviando-as para seu companheiro confiável, o InfluxDB.
InfluxDB: Um banco de dados otimizado para armazenar métricas de séries temporais (dados que têm um carimbo de tempo). É aqui que guardamos todas as informações coletadas pelo Telegraf. Imagine um cofre gigante de dados temporais.
Grafana: A artista da turma! Ela pega todas as informações armazenadas pelo InfluxDB e cria gráficos e dashboards visualmente incríveis. Vocês vão ver….
Com esse time instalado e configurado corretamente, e certamente mais alguns passos, estaremos com poucos cliques, monitorando VMware vSphere.
OBS: Esse time é capaz de monitorar muitas coisas, não apenas VMware vSphere. Algumas da qual pretendo detalhar em outros artigos, como por exemplo: Servidores Windows e Linux, Veeam Backup, Active Directory, Switchs, Roteadores, Docker, Dispositivos que aceitem SNMP, etc….
Passo 1: Montando a Estrutura
Primeiro, vamos criar algumas pastas para manter tudo organizado:
mkdir -p docker/monitoring cd docker/monitoring

Passo 2: O Grande Truque (docker-compose.yml)
O arquivo docker-compose.yml é o coração da nossa operação. Ele define como os conteiners do nosso stack serão executados.
E do que se trata esse arquivo?
No artigo anterior, eu detalhei o que é o Docker Compose e disse que mais na frente seria mais fácil de entender. Lembram-se?
O Docker Compose é uma ferramenta que permite definir e gerenciar aplicações multi-container Docker. Você leu lá em cima que o TIG Stack é composto de 03 conteiners certo, e eles são independentes, ou seja, não sao obrigados serem instalados juntos. E aqui que entra a principal função do Docker Compose: de forma simples, ao invés de subir cada container manualmente com uma infinidade de comandos e opções, você cria uma receita de como deseja que seus containers funcionem em um único arquivo chamado: docker-compose.yml
Com esse arquivo, você:
Define seus containers e suas configurações em um único arquivo.
Inicia todos os serviços com um único comando: docker compose up
Pode parar todos os serviços com um comando simples: docker compose stop
Pode reiniciar todos os serviços com um comando simples: docker compose restart
A estrutura e formato .yml (que significa “YAML Ain’t Markup Language“) é intuitivo e fácil de entender, estruturando a informação de uma forma que nós humanos (não apenas máquinas) podemos entender. Nele declaramos os serviços (containers) que iremos subir. Um ponto importante é que esse arquivo deve ficar no diretório raiz do projeto, no meu caso está em /home/leandro/docker/monitoring tendo em vista que estou seguindo meu laboratório e uma cronologia dos artigos que venho escrevendo.
Agora que entendemos o básico, vamos criar nosso arquivo docker-compose.yml
nano docker-compose.yml
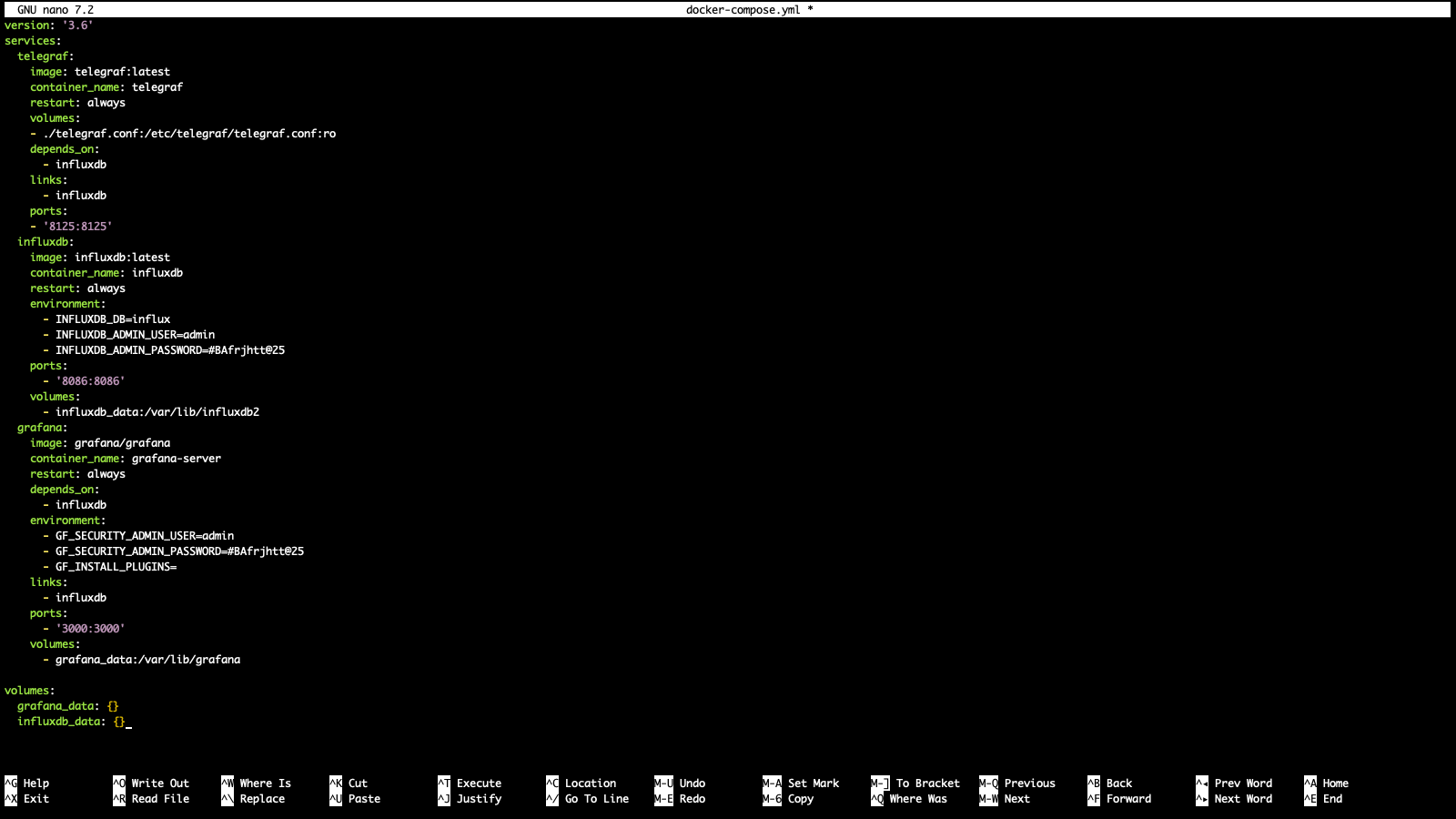
Insira o conteúdo abaixo:
version: '3.6'
services:
telegraf:
image: telegraf:latest
container_name: telegraf
restart: always
volumes:
- ./telegraf.conf:/etc/telegraf/telegraf.conf:ro
depends_on:
- influxdb
links:
- influxdb
ports:
- '8125:8125'
influxdb:
image: influxdb:latest
container_name: influxdb
restart: always
environment:
- INFLUXDB_DB=influx
- INFLUXDB_ADMIN_USER=admin
- INFLUXDB_ADMIN_PASSWORD=P@$$w0rd
ports:
- '8086:8086'
volumes:
- influxdb_data:/var/lib/influxdb2
grafana:
image: grafana/grafana
container_name: grafana-server
restart: always
depends_on:
- influxdb
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=P@$$w0rd
- GF_INSTALL_PLUGINS=
links:
- influxdb
ports:
- '3000:3000'
volumes:
- grafana_data:/var/lib/grafana
volumes:
grafana_data: {}
influxdb_data: {}
Vamos explorar os pontos principais?
É aqui que a mágica acontece! As configurações definidas aqui diz ao Docker o que exatamente você quer que ele faça.
services: nós definimos nesta secão os três serviços: telegraf, influxdb e grafana.
image: aqui você define a imagem do serviço (conteiner) que você deseja usar no Docker Hub, você também define a versão que deseja. Esse nome latest é um tag que geralmente aponta para a versão mais recente da imagem.
container_name: Aqui você define o nome do container que você deseja que seja, você define a seu gosto. Facilita a identificação e gestão do container. Se você não colocar nada, o Docker gerará um nome aleatório.
restart: Faz com que o container sempre reinicie se ele parar por qualquer motivo, você não vai querer ficar iniciando esse serviço manualmente.
volumes: Aqui mapeamos um arquivo ou diretório do seu serviço, você precisa dizer para seu conteiner onde você deseja armazenar os arquivos/pastas e/ou você aponta um arquivo de configuração, caso necessário.
depends_on: Aqui definimos a dependência de inicialização dos serviços. No nosso caso, o serviço telegraf só será iniciado depois do InfluxDB tiver iniciado. Aqui se parece com as dependências de serviços no Windows.
links: Define uma conexão de rede entre containers, fazendo com que eles se comuniquem entre si.
ports: Mapeia uma porta no host (em nosso caso é o Raspberry Pi) para uma porta no container.
environment: Define as variáveis de ambiente para a configuração inicial. Essas variáveis vai depender do conteiner (serviço).
volumes: Diferente lá de cima, estes são volumes nomeados. eu já referenciei eles nas seções de serviço acima. Eles serão usados para armazenar dados persistentes para os respectivos serviços, permitindo assim que os dados persistam mesmo após os containers serem parados ou excluídos.
Agora vamos criar o arquivo telegraf.conf necessário para a instalação do serviço Telegraf:
nano telegraf.conf
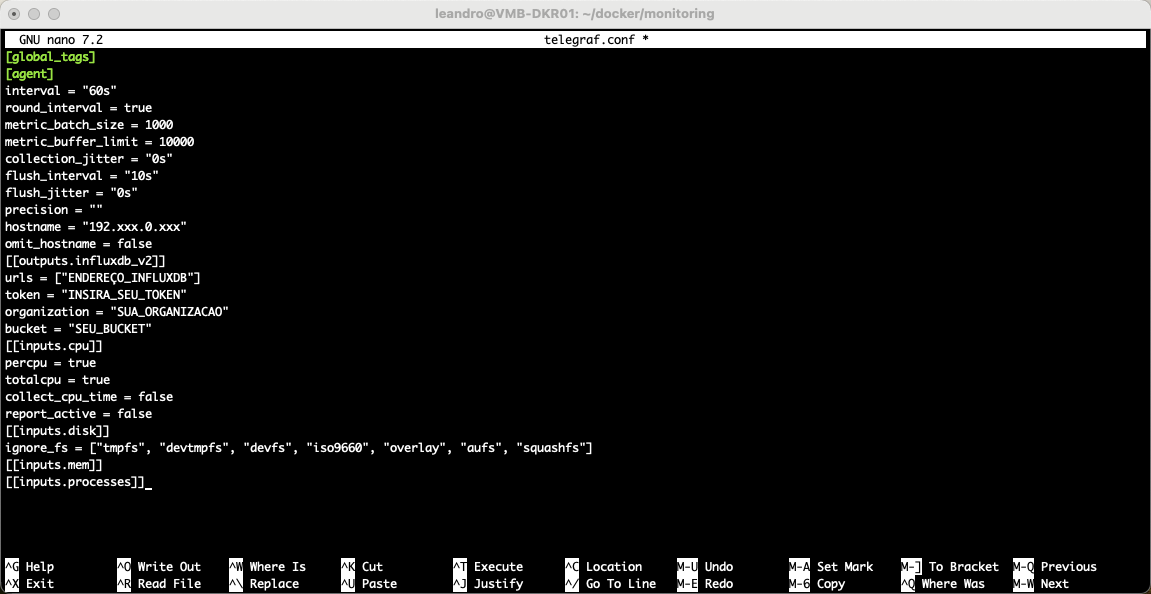
Insira o conteúdo abaixo:
[global_tags] [agent] interval = "60s" round_interval = true metric_batch_size = 1000 metric_buffer_limit = 10000 collection_jitter = "0s" flush_interval = "10s" flush_jitter = "0s" precision = "" hostname = "192.xxx.0.xxx" omit_hostname = false [[outputs.influxdb_v2]] urls = ["ENDEREÇO_INFLUXDB"] token = "INSIRA_SEU_TOKEN" organization = "SUA_ORGANIZACAO" bucket = "SEU_BUCKET" [[inputs.cpu]] percpu = true totalcpu = true collect_cpu_time = false report_active = false [[inputs.disk]] ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"] [[inputs.mem]] [[inputs.processes]]
Após criar o arquivo docker-compose.yml e o telegraf.conf vamos executar o comando simples, porém poderoso para dar vida aos nossos conteiners.
docker compose up -d
Observe a mágica acontecer:
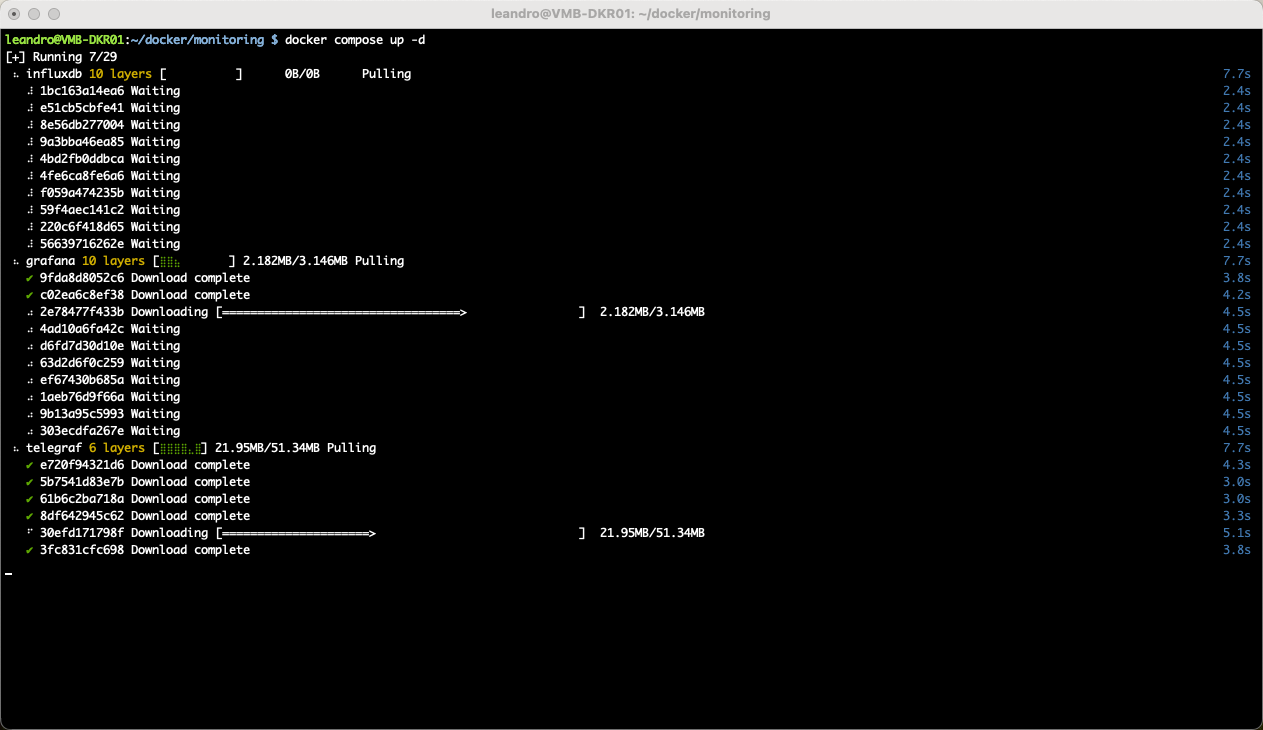
Passo 3: Integrando o Telegraf com o InfluxDB
O que fizemos até agora foi apenas subir nossos serviços, resta configurar eles e realizar as integrações necessárias.
Acesse o InfluxDB usando o IP do seu Raspberry Pi com a porta 8086 que foi definida no arquivo docker-compose.yml, como por exemplo: http://192.168.68.135:8086
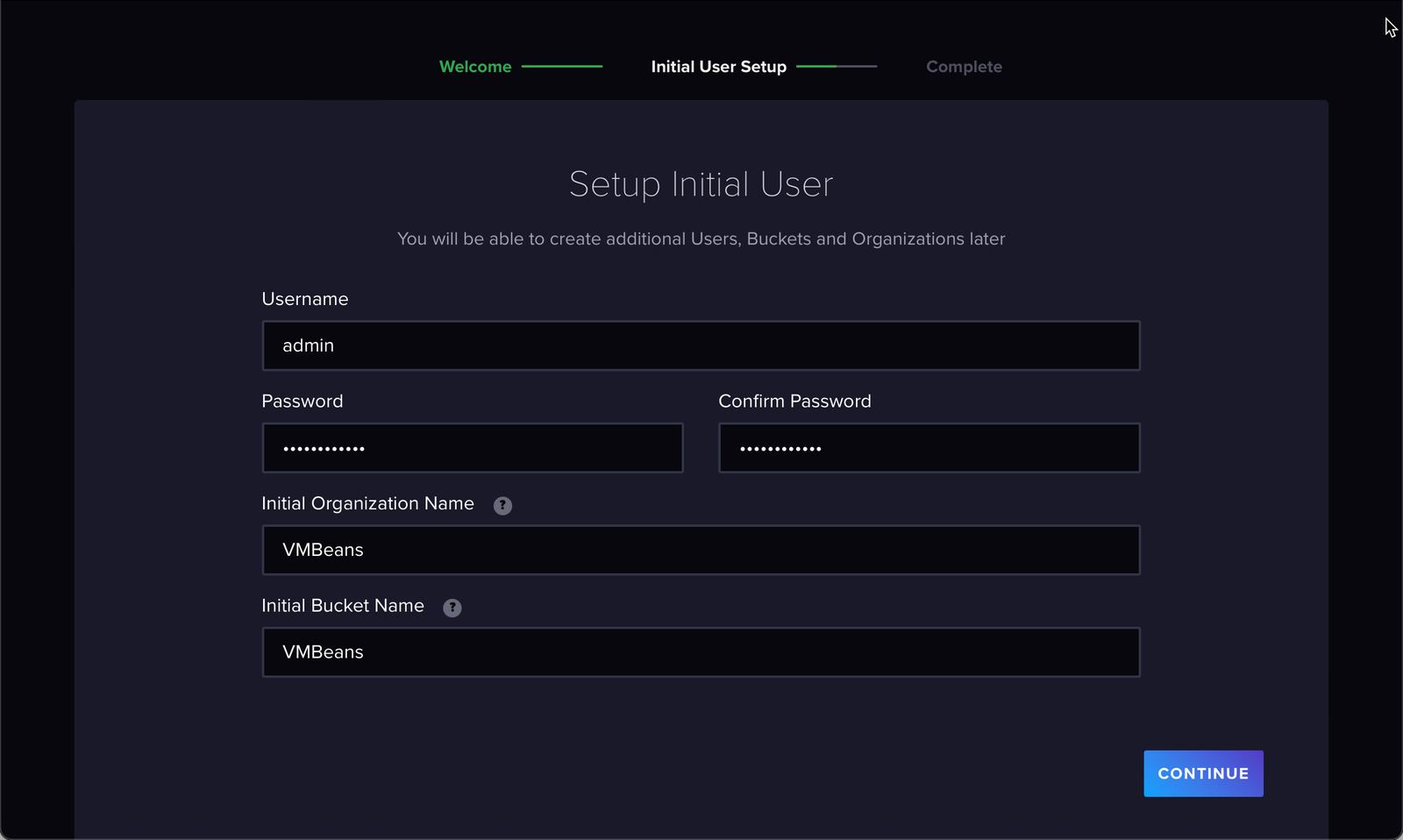
Ao se logar, defina os dados abaixo:
usuário: admin
senha: P@$$w0rd
organization: VMBeans
bucket: VMBeans
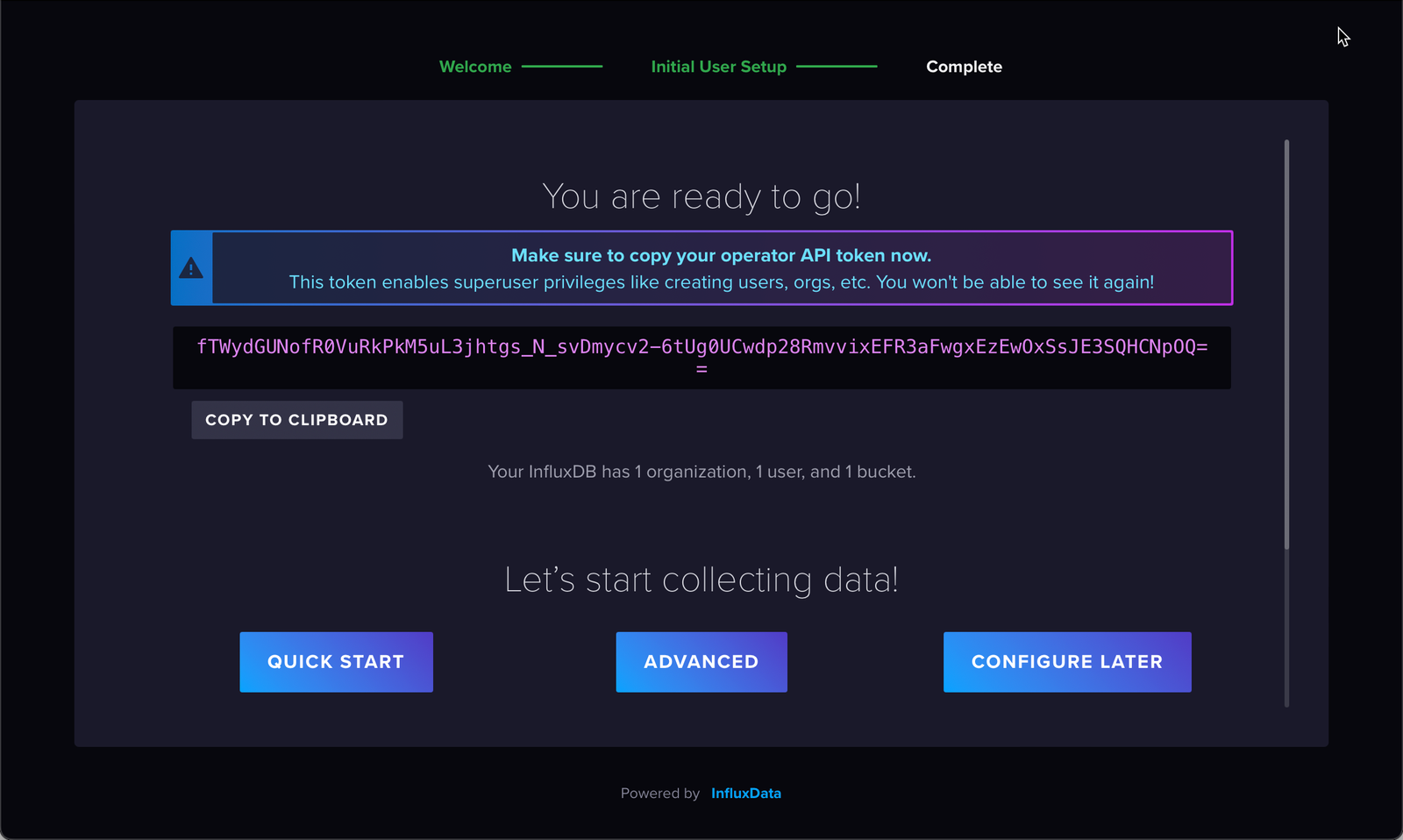
Após se logar, não se esqueça de salvar o token! Ele é como um passe especial que permite ao Telegraf falar com o InfluxDB.
Agora de posse do token gerado no InfluxDB e das configurações que definimos no primeiro acesso, precisamos editar o arquivo de configuração Telegraf:
nano telegraf.conf
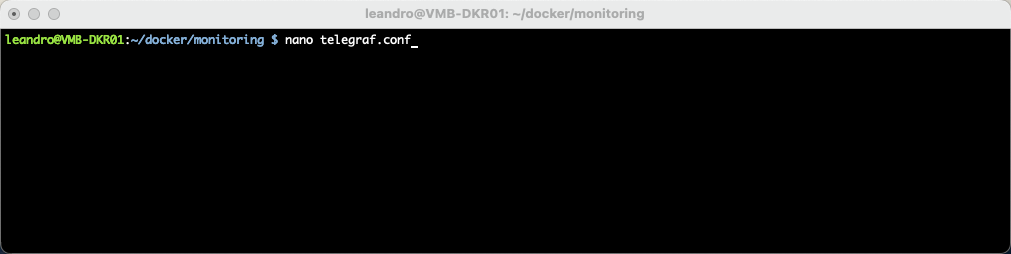
Você precisa se atentar aos campos que irão fazer a integração com o InfluxDB, ou seja, o Telegraf vai coletar as métricas e alimentar no banco de dados InfluxDB, na qual essa conexão irá depender desses itens. Eu preenchi os itens para lhe servir de exemplo, são os que estão comentados no arquivo de configuração, voce altera de acordo com seu ambiente.
[[outputs.influxdb_v2]] urls = ["http://192.168.68.135:8086"] #Aqui se refere ao endereço do seu InfluxDB token = "INSIRA_SEU_TOKEN" # Aqui voce precisa inserir o token gerado no passo anterior ao acessar o InfluxDB organization = "VMBeans" # A organizacao que voce definiu, nesse caso estou usando um nome da minha empresa ficticia do meu lab bucket = "VMBeans" # O bucket que voce definiu também, nesse caso estou usando um nome da minha empresa ficticia do meu lab tambem
Agora que voce configurou o Telegraf para enviar os dados coletados para o InfuxDB, precisamos reiniciar o serviço do Telegraf para efetivar.
Basta usar o comando abaixo:
docker compose restart telegraf
Passo 4: Integrando o Grafana com o InfluxDB
O último do time a ser integrado no TIG Stack.
Vamos acessar o Grafana, conforme porta que configuramos no docker-compose.yml e instruir o Grafana a utilizar o banco de dados InfluxDB como origem de métricas para seus dashboards:
http://192.168.68.135:3000
Ao se logar, na pagina inicial, voce clica em DATA SOURCES:
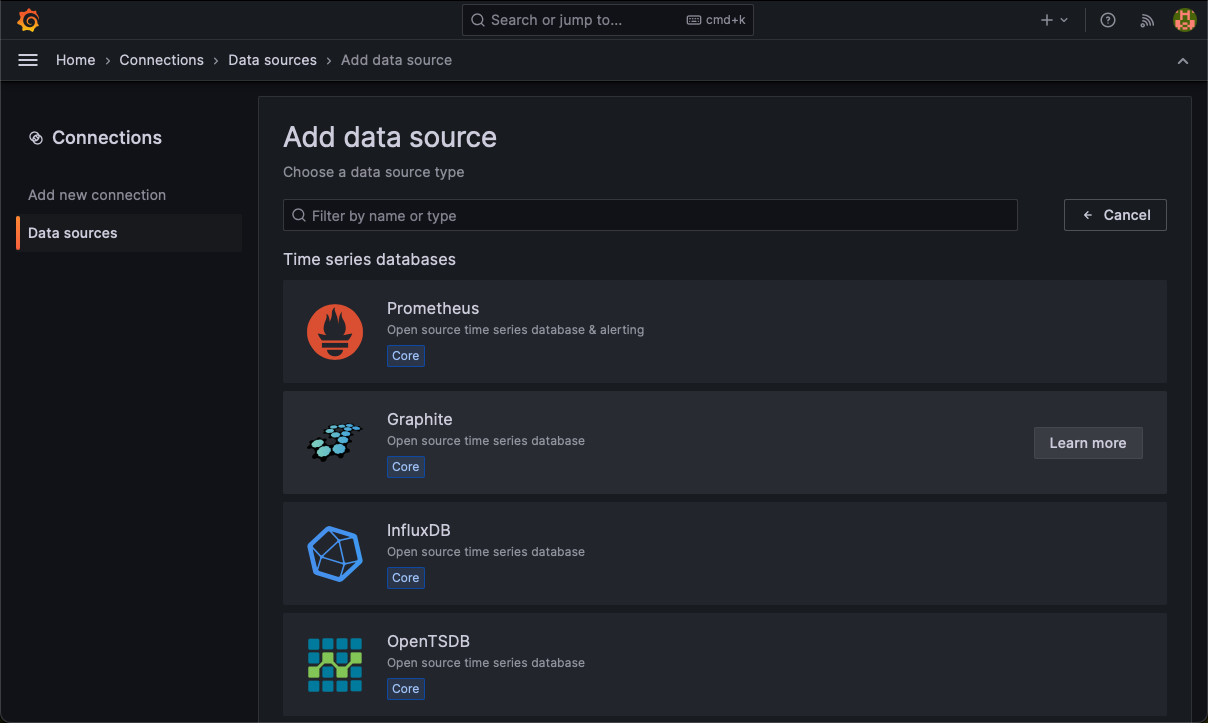
Na tela seguinte, vamos selecionar nosso banco de dados InfluxDB:
Nesta tela, precisamos preencher apenas os campos abaixo, conforme imagem:
Query Language: Flux
URL: http://192.168.68.135:8086
User: admin
Password: P@$$w0rd
Organization: VMBeans
Bucket: VMBeans
Token: o mesmo token gerado la no InfluxDB que foi criado no primeiro login
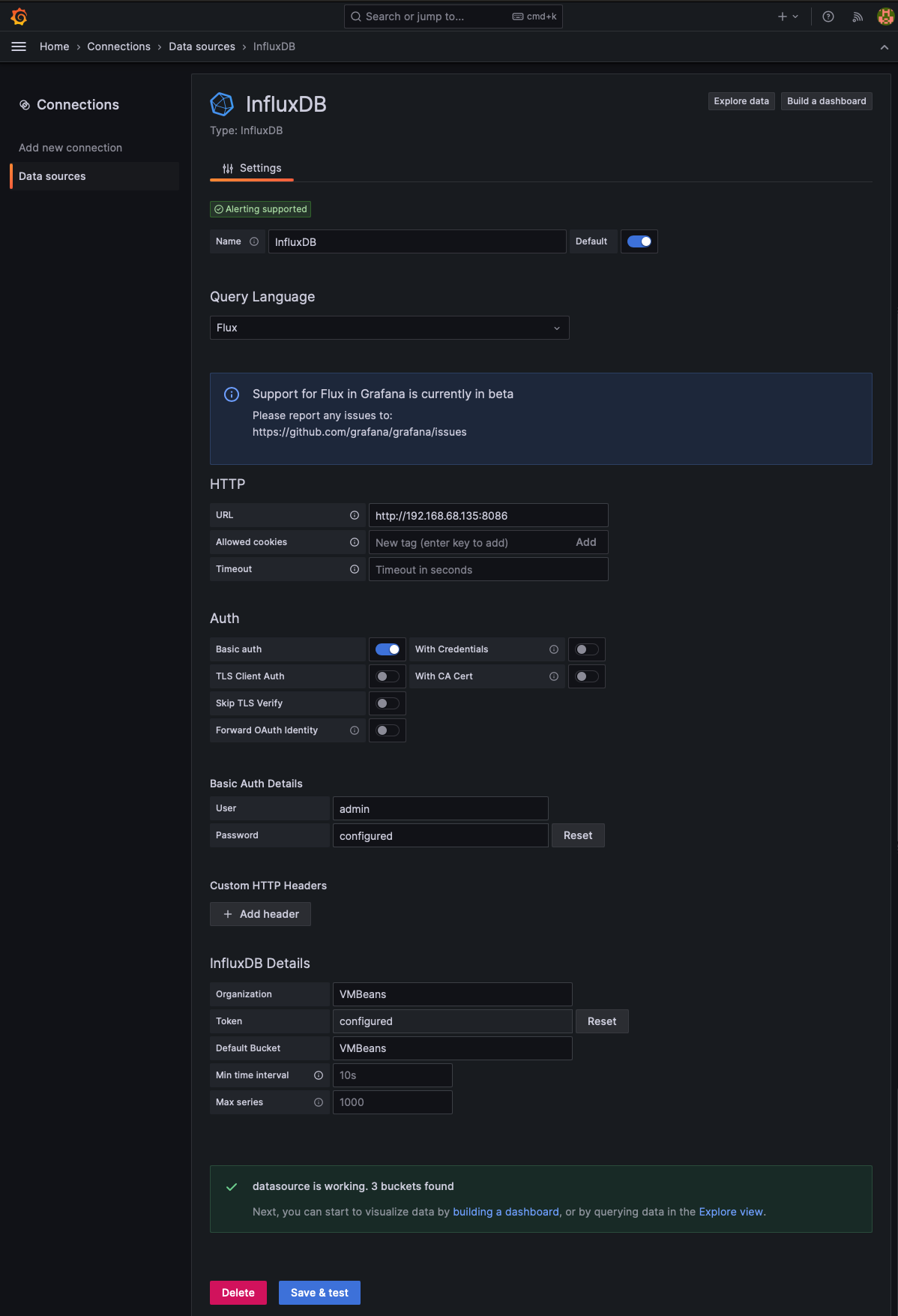
Ao clicar em Save & test deverá aparecer essa confirmação da cor verde, informando que o Data Source ocorreu com sucesso, ou seja, que o Grafana será capaz de consultar dados do InfluxDB.

Caso apareça esse alerta de erro, significa que não foi possível estabelecer comunicação entre o Grafana e o InfluxDB, é preciso que voce cheque os itens que informei acima.

Até aqui, finalizamos a instalação e configuração padrão do TIG Stack.
Estamos prontos para monitorar uma infinidade de soluções com o Telegraf como agent de coleta, InfluxDB armazenando essas métricas coletadas no Telegraf, e o Grafana dando vida com seus dashboards.
Passo 5: Coletando métricas do VMware vSphere e apresentando via dashboards com Grafana
Nesse ultimo passo será a cereja do bolo desse artigo, vamos iniciar instruindo o agent Telegraf a coletar dados do seu VMware vCenter.
Vale lembrar que essa integração é oficial, homologada pelo próprio VMware através do projeto govmomi e compatível com vSphere versão 6.5, 6.7, 7.0 e 8.0
Para essa coleta, vamos editar o arquivo telegraf.conf:
nano telegraf.conf
Vamos inserir no fim do arquivos, os parâmetros abaixo:
Basta voce alterar apenas os seguintes campos:
vcenters = [ “https://IP_DO_SEU_VCENTER/sdk” ]
username = “USUARIO_VCENTER”
password = “SENHA_ACESSO_VCENTER”
## Instância em tempo real [[inputs.vsphere]] interval = "60s" vcenters = [ "https://192.168.68.140/sdk" ] username = "administrator@vsphere.local" password = "P@$$w0rd" insecure_skip_verify = true # Ignora o erro de certificado do seu vCenter force_discover_on_init = true # Exclude all historical metrics datastore_metric_exclude = ["*"] cluster_metric_exclude = ["*"] datacenter_metric_exclude = ["*"] resource_pool_metric_exclude = ["*"] vsan_metric_exclude = ["*"] collect_concurrency = 5 discover_concurrency = 5 # Instância em Histórico [[inputs.vsphere]] interval = "300s" vcenters = [ "https://192.168.68.140/sdk" ] username = "administrator@vsphere.local" password = "P@$$w0rd" insecure_skip_verify = true # Ignora o erro de certificado do seu vCenter force_discover_on_init = true host_metric_exclude = ["*"] # Exclude realtime metrics vm_metric_exclude = ["*"] # Exclude realtime metrics max_query_metrics = 256 collect_concurrency = 3
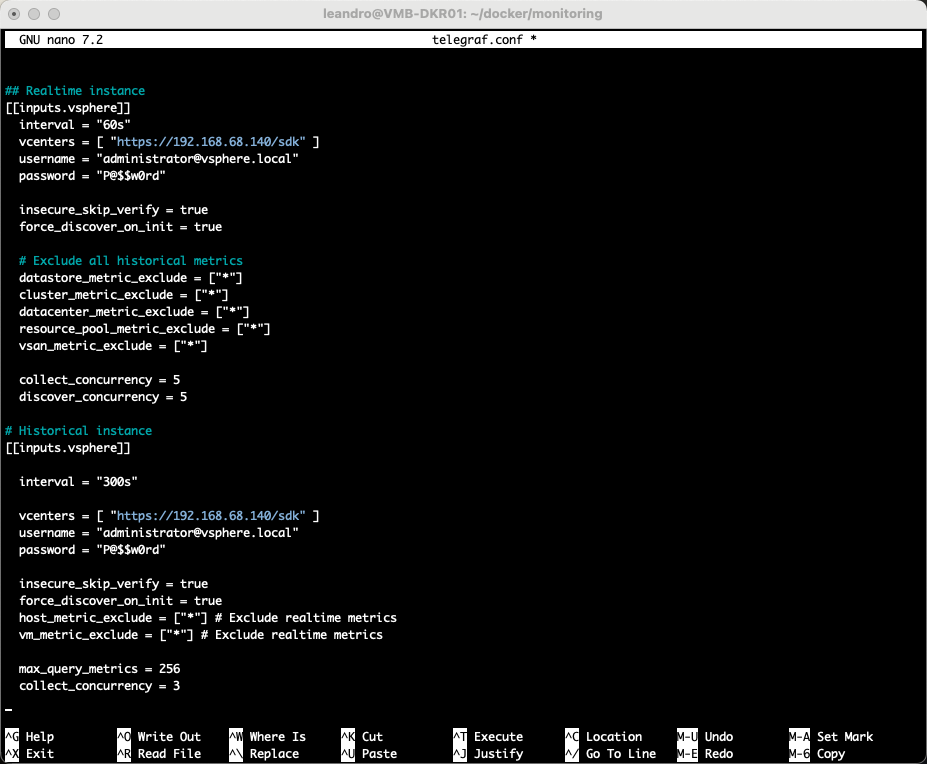
Uma breve explicação desses parâmetros que são muito subjetivos é a respeito do acesso do seu vCenter. Embora eu tenha colocado o Administrator, não é obrigatório e nem recomendado utilizar ele, pois como se trata apenas de consulta, basta você criar um usuário apenas leitura no seu vCenter e atribuir nesses campos. Após salvar o arquivo, você precisa reiniciar o telegraf:
docker compose restart telegraf
Após esse passo, basta criarmos nossos dashboards no Grafana.
Mas porquê faríamos isso, se nosso amigo Jorge de la Cruz já criou para a gente?
Iremos apenas importar de forma fácil e simples. Não precisamos reinventar a roda….
Logar no Grafana, expandir a barra lateral esquerda e clicar em Dashboards:
Clicar em New > Import
No campo “Import via grafana.com” você vai inserir o link abaixo, e clicar em Load:
https://grafana.com/grafana/dashboards/8159
Na tela seguinte, você precisa apenas selecionar o data source “InfluxDB” que havíamos criado e clicar em Import:
Você vai repetir esses passos para cada link abaixo:
https://grafana.com/grafana/dashboards/8165
https://grafana.com/grafana/dashboards/8168
https://grafana.com/grafana/dashboards/8162
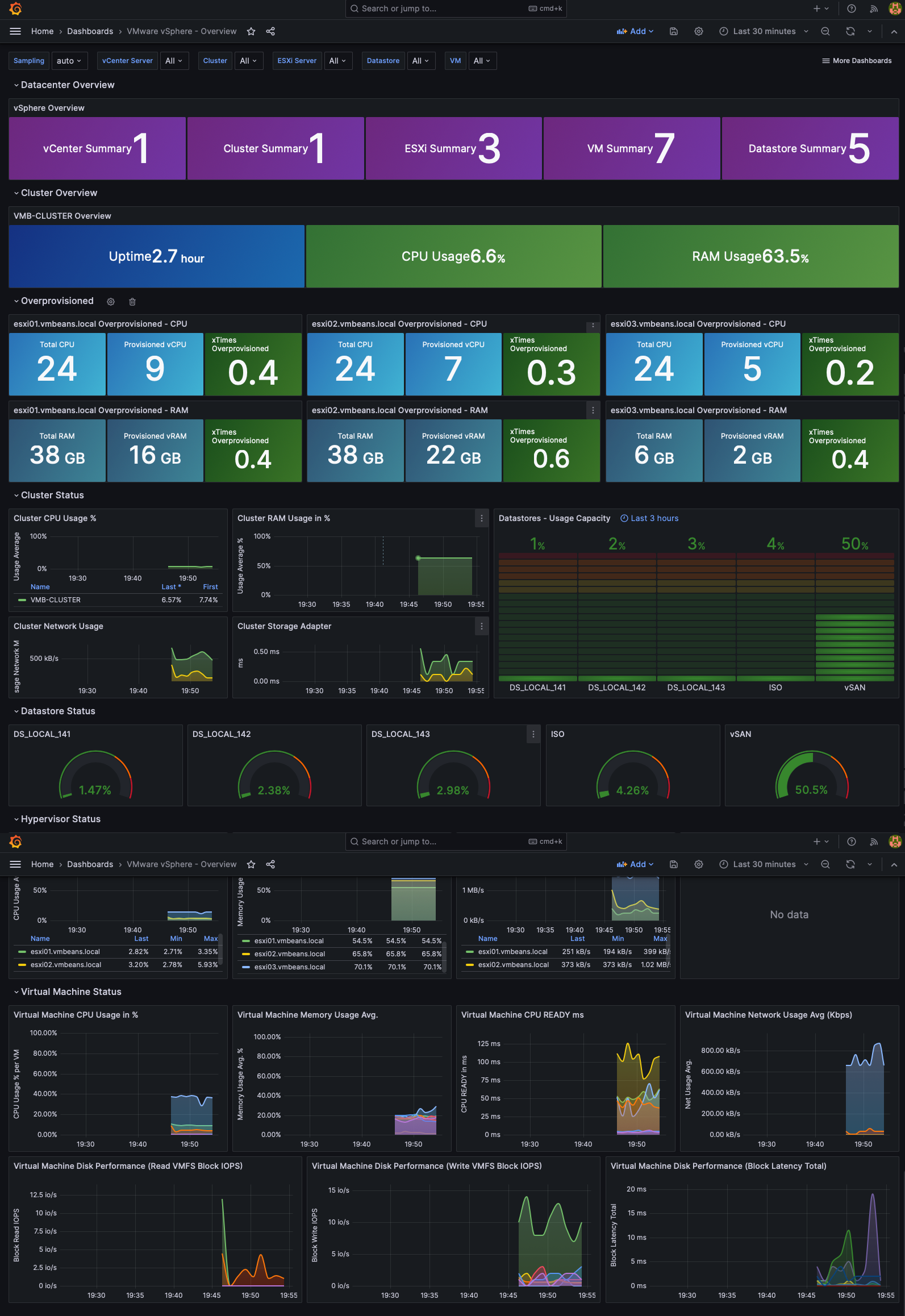
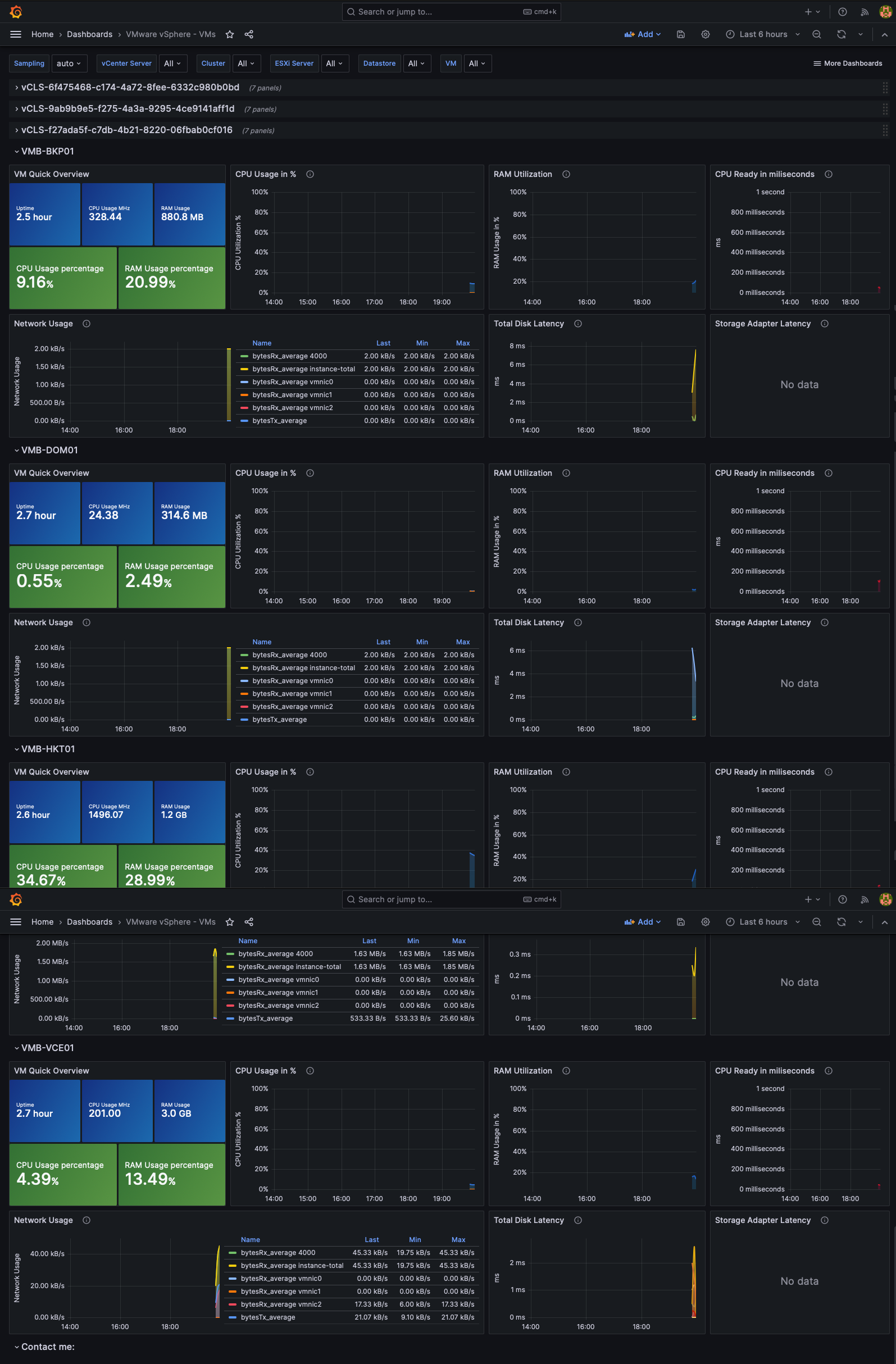
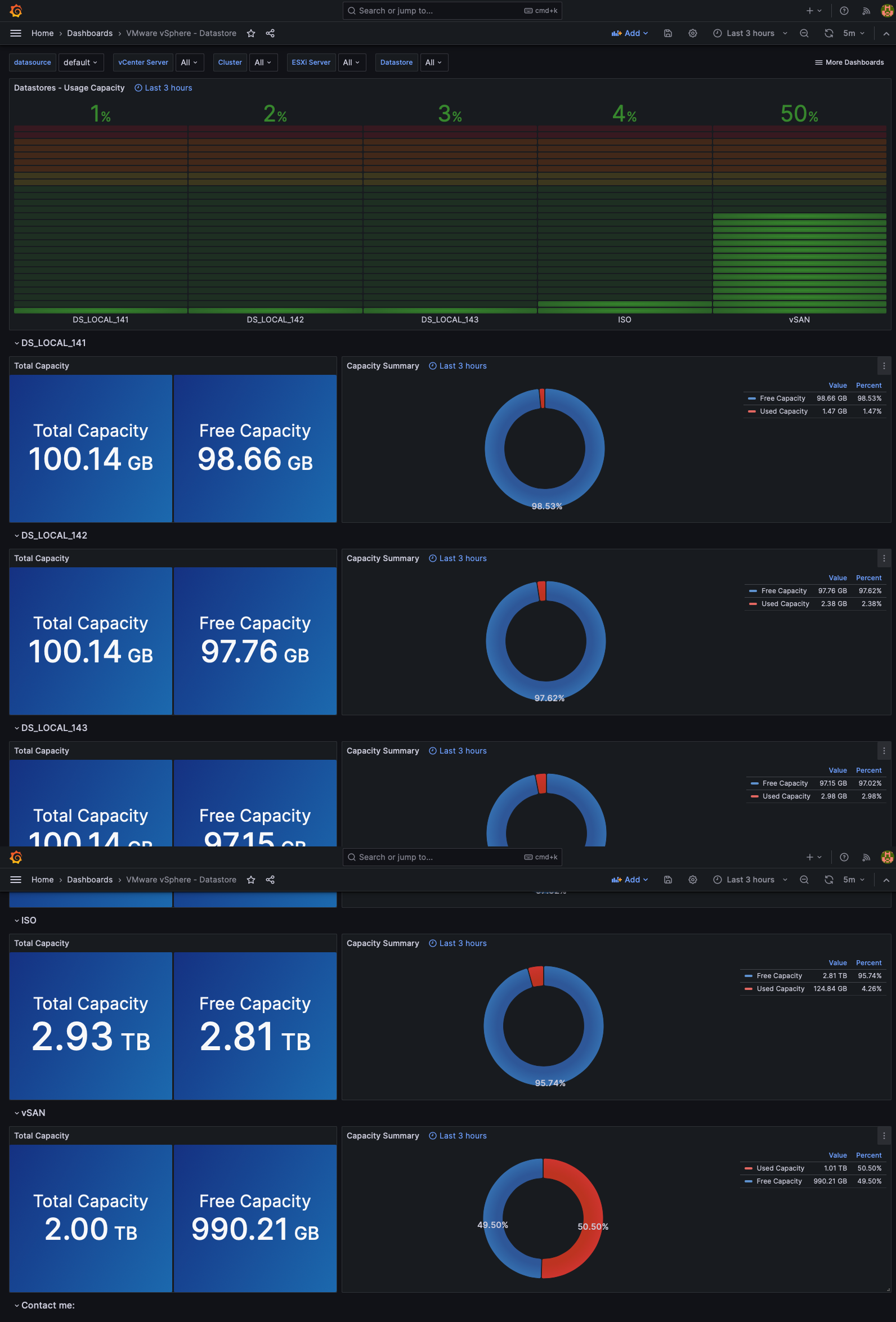
Segue abaixo o resultado final, ou seja, com esses Dashboards, podemos ter uma visão do nosso ambiente VMware vSphere.
VMware vSphere Overview
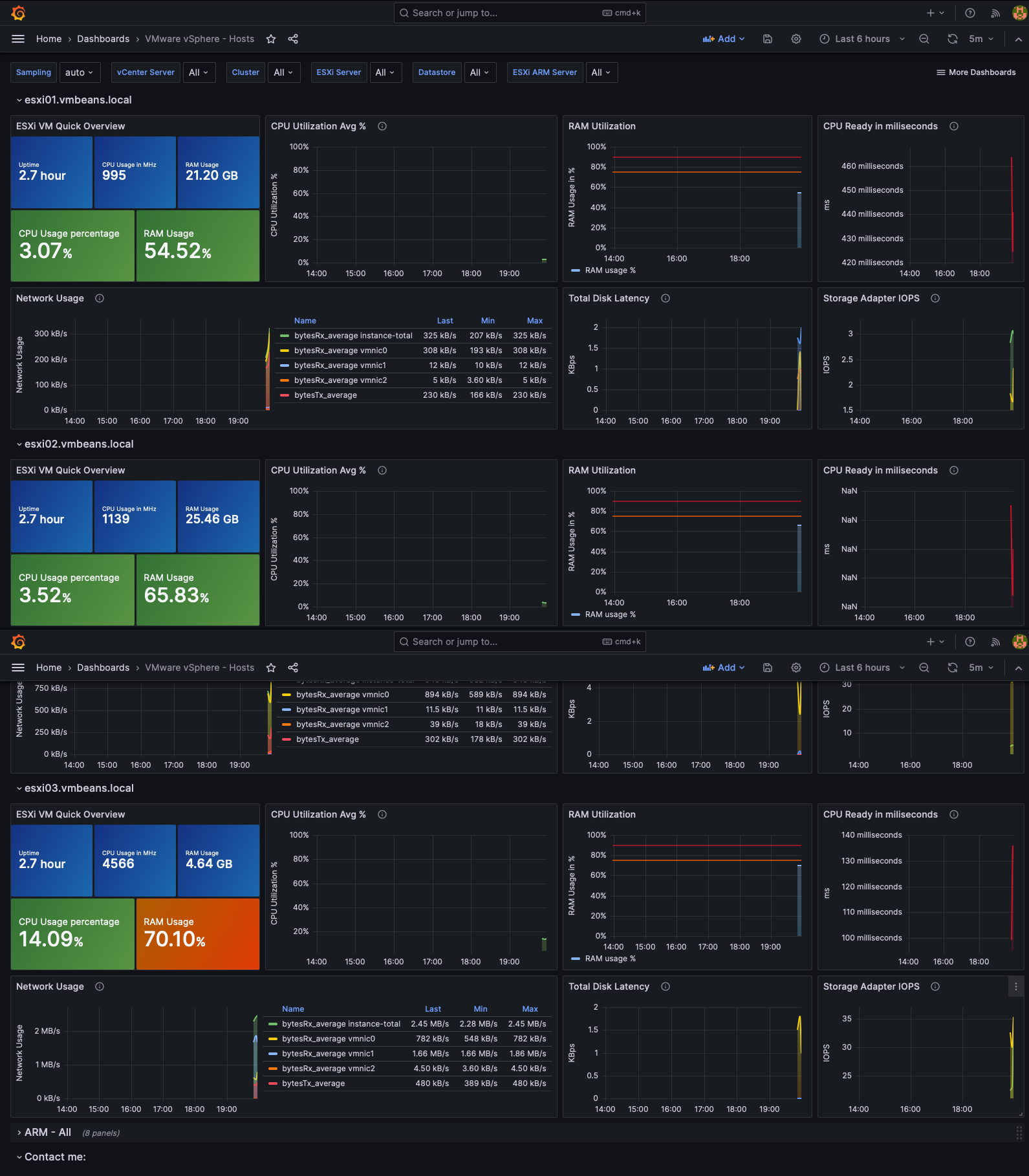
VMware vSphere Hosts
VMware vSphere Virtual Machines
VMware vSphere Datastores
Concluindo:
Finalmente! Posso dizer que montamos uma agência de monitoramento no nosso Raspberry Pi 4, solução robusta e econômica. Agora, devemos desfrutar dos dashboards criadas pelo Grafana para monitoramento do seu ambiente VMware vSphere. Agora podemos dizer que estamos monitorando VMware vSphere. Mas peraí, e se eu quiser usar essa mesma agencia para monitorar outras soluções de infraestrutura da minha empresa? Claro, tenho alguns insights aqui comigo, veremos isso nos próximos artigos. 🕵️♂️🔍